ShapeKit Loader¶
Data sets¶
Quoting mediawiki, “Supervised learning is the machine learning task of inferring a function from supervised training data”. Such a function has a number of inputs and a number of outputs. The data set (which in many case will be a training set, but it could also be a validation set for example) consists of several lines, or experiments which provide the desired output values when the input values are provided to the function. Most of the time those values come from actual physical experiments and both input and output values may include some error.
A very simple example could be the following:
| X1 | X2 | X3 | X4 | X5 | Y |
|---|---|---|---|---|---|
| 28 | 11 | 18 | 79 | 17 | 32 |
| 26 | 4 | 27 | 79 | 16 | 51 |
| 29 | 14 | 53 | 82 | 29 | 73 |
| 38 | 12 | 63 | 85 | 39 | 84 |
| 45 | 6 | 47 | 84 | 38 | 85 |
The function f that we want to find has 5 inputs and 1 output, and our experiments say that f (29,14,53,82,29)=73.
Actual dataset found in the industry have a lot more lines (typically between 104 and 106). The number of inputs and outputs vary greatly, but is often not big. Having too much inputs, typically, is an indication that the preliminary work by specialists of the field should be improved.
The purpose of the ShapeKit Loader is to create a well formed Dataset for supervised learning. A well-formed Dataset is defined as
- There is at least one entry with non null standard deviation
- There is at least one output with non null standard deviation
Comma-separated values¶
The loader reads data from CSV files (comma-separated value) that are either exported from spreadsheets or created by the experiment tools/probes. It can of course also read ShapeKit Xml and Binary files. It is highly recommended to only use raw data at this point. That means, do NOT apply any processing to your data, such as normalization or PCA).
The program will tell you if a column is degenerated and hence useless. That is, if all values are equal (Standard Deviation = 0).
CSV is not a well defined standard, and CSV files can actually be very different from one another. The ShapeKit Loader tries to be as tolerant as possible concerning CSV files. For example, as far as it is not ambiguous (with decimal separator) and consistent among the whole file, the delimitor can be any of
- comma (,)
- colon (:)
- semicolon (;)
- tab
If the first line contains labels (names) for the column, ShapeKit Loader will use those names as default column names and will handles simple or double-quotes gracefully. The file can contain blank lines, they will be ignored, just as leading spaces or spaces at start of lines.
In any case, if a problem is too important and prevent reading the CSV file, a (hopefully) clear description of what the problem is will be displayed in a dialog box.
A CSV file for the previous data set example could then be:
'X1';'X2';'X3';'X4';'X5';'Y'
28;11;18;79;17;32
26;4;27;79;16;51
29;14;53;82;29;73
38;12;63;85;39;84
45;6;47;84;38;85
But also:
X1 : X2 : X3 : X4 : X5 : Y
28 : 11 : 18 : 79 : 17 : 32
26 : 4 : 27 : 79 : 16 : 51
29 : 14 : 53 : 82 : 29 : 73
38 : 12 : 63 : 85 : 39 : 84
45 : 6 : 47 : 84 : 38 : 85
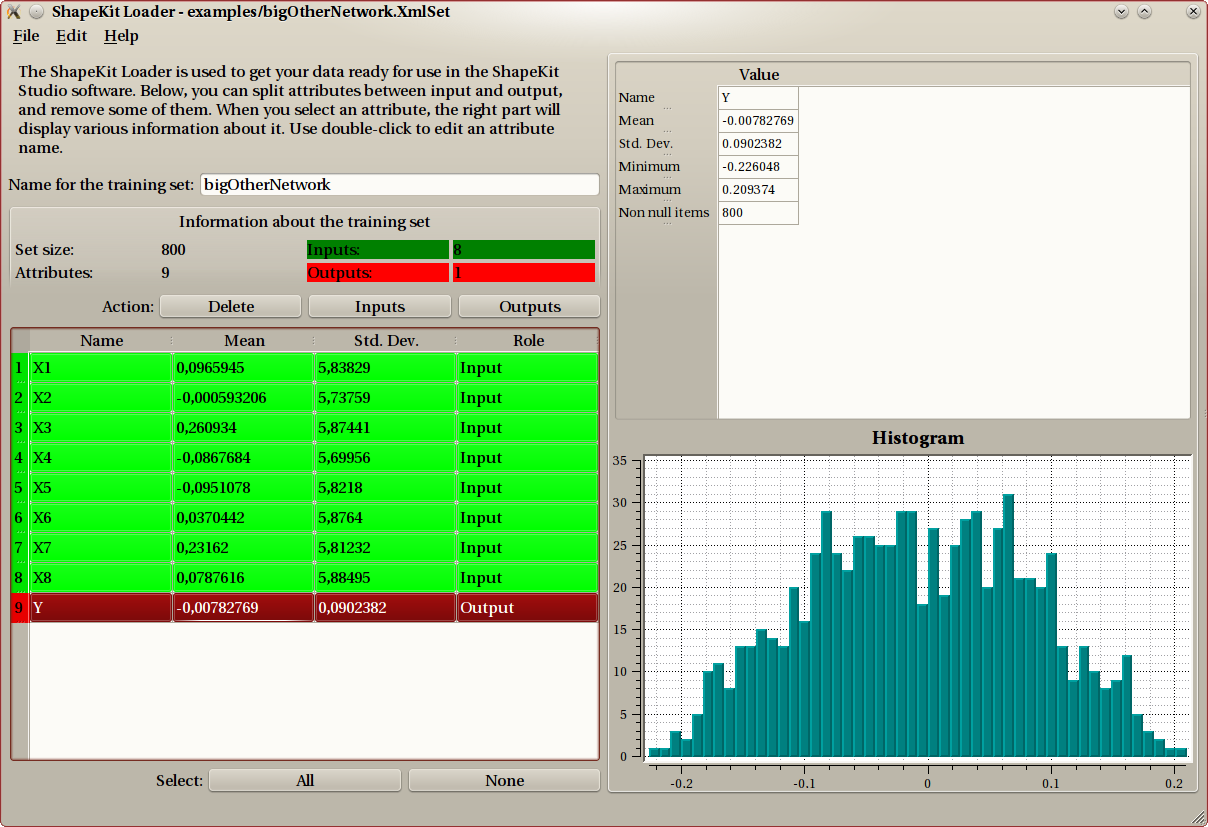
Graphical interface¶
When a file is loaded, whatever it is, the list of data columns is displayed on the bottom-left table with some statistical data. When you click/select a column, some more information is displayed on the right panel, such as an histogram of the values.
The actions you can perform are:
- delete a column
- classify a column as input or output
- change the name of the dataset, the default value is the name of the CSV file without extension.
- change the name of columns: double click on the name
Once done, you can save your data in file that can be used by ShapeKit Studio or ShapeKit Exploiter. The output file is called a ShapeKit Dataset and can be either
- an XML file (extension .XmlSet). It is slightly bigger but is more suitable for human reading, script-editing or storing in a revision control system. You can easily make your own scripts output such a file in order to ease integration with ShapeKit Suite.
- a binary file (extension .BinarySet) : those are compact and efficient and especially recommended when storing huge data sets. Those files are already compressed so you wont gain anything in compressing them with ZIP or any other compression software.
Those file can be stored and exchanged as any other file. As a convenience, you can also export as CSV, although this is not a feature needed by other programs from the suite.
As an example, a data set with 784 inputs, 10 outputs, and 6000 rows of data is worth
- 11 Mb if stored as an XmlSet (~25k lines)
- 1.8Mb if stored as a BinarySet
Browser¶
There is also a browser that you can use to see all values. This is usually not needed.
We do not recommend starting the data browser if the data set contains too much data : this would require a lot of memory and could slow down the computer very much.